Hard to explain, easy to verify
It’s January 2023, and— in the AI community— everything feels possible again.
In the past few months, the democratization of image generation models and improved usability of language models ushered in a wave dubbed “Generative AI”.
Speculation abounds for the potential applications of AI: copilots for every profession, next-generation chatbots, and more.
Key Pattern for AI Tasks
Amid this speculation, I think tasks that feel practically useful to complete with AI follow one pattern, which I call “hard to explain, easy to verify”. A task fits this pattern if it is:
- Hard to explain how to complete the task
- Easy to verify the task outcome is correct
There aren’t absolute thresholds for “hard” and “easy”; it depends on a task owner’s skills and their next best alternative to AI for completing the task.
Note that “hard to explain” describes the process underlying the task (i.e. how to complete it), not the outcome of the task (i.e. what success looks like).
Examples
This pattern is most vivid in the early applications for which “Generative AI” has captured the market:
-
Text - Whether it’s for marketing copy or fiction, it’s hard to explain how to write something well, but easy to verify it’s written well.
-
Images - It’s hard to explain all the steps to draw a cat in the style of an oil painting. But if I showed you one, it’d be easy to verify it depicts what I claim.
-
Code - Given an IDE context, it’s hard to explain how to produce the next line of code. But when GitHub Copilot suggests a code block, it’s easy to verify by inspecting the code and/or running it.
I think the pattern also applies to earlier applications of AI.
For example, it’s hard to explain all the specific actions needed to drive between two points. But it’s easy to tell whether a self-driving car succeeded based on whether it reached its destination, hit anything, or broke traffic laws.
Why It Matters
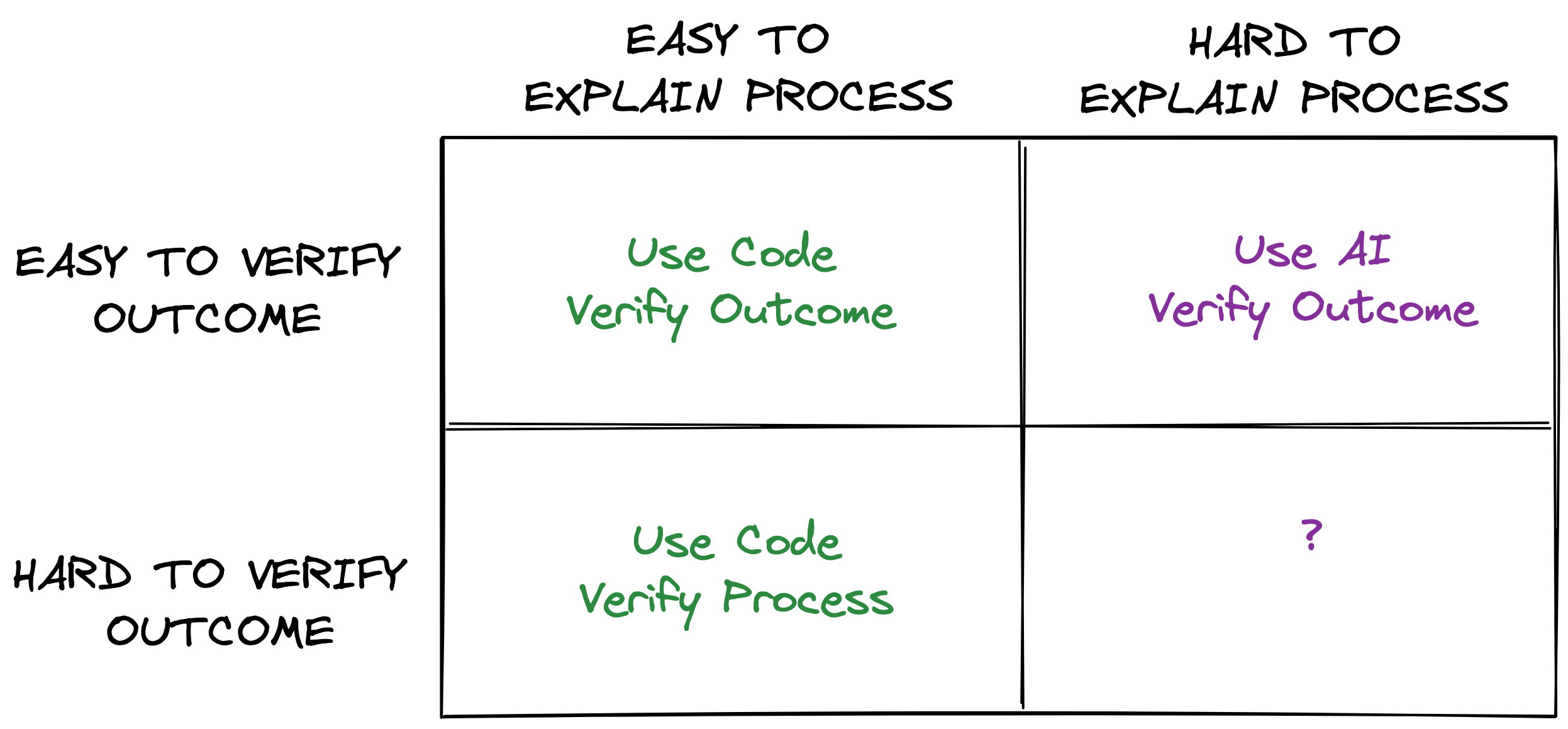
A task fit for AI should be “hard to explain” because, if it were easy to explain, traditional code would be preferred to complete the task reliably. Code would be the explanation for how to complete the task.
A task fit for AI should be “easy to verify” because— when we complete tasks— we choose to verify either the process or the outcome for correctness. When we write code, we usually verify the process by inspecting its logic and writing tests.
When we utilize AI, the process (e.g. neural network) is too complex to verify for correctness. We instead verify the outcome by inspecting the model’s output. This output must be easy to verify for the application of AI to feel worthwhile.
Non-Examples
Easy to Explain, Easy to Verify
This category is relatively small compared to the next one, but an example would be a program that prints “Hello, world!” five times.
Easy to Explain, Hard to Verify
Most tasks for which we write code fall into this category. For example, mathematical computation (e.g. what is 537 + 6872?) is easy to explain, but the outcome is hard to verify because doing so requires repeating the work inherent in the original task. We’d rather verify the process (e.g. inspect code, write tests).
Open Question
Hard to Explain, Hard to Verify?
The nature of this final quadrant stumps me.
On one hand, AI is a candidate because the task process is hard to explain. On the other hand, it’s unclear we’d be able to sufficiently monitor the process for correctness.
Ought is doing interest work exploring applications of AI where outcomes are hard to verify, like long-term forecasting and policy development.
I’m not confident there are tasks in this quadrant for which it would be practically useful to complete with AI, but I’m open to being convinced otherwise as research plays out here.
If you have thoughts about any of this, let me know.
January 2023